Kể từ khi GPU được cho phép để lập trình, phạm vi ứng dụng của nó ngày càng rộng hơn. Ngoài các ứng dụng AI phổ biến nhất hiện nay, vẫn còn nhiều lĩnh vực yêu cầu GPU để giảm thời gian tính toán. Cho dù đó là giải quyết vấn đề phân tích phần tử hữu hạn trong hoạt động khoa học, hoặc so sánh DNA trong kỹ thuật sinh học; thậm chí các nhà thiết kế còn sử dụng phần mềm để tăng tốc kết xuất các mô hình CAD đã hoàn thành bằng công nghệ Ray Tracing. Bởi vì các ứng dụng này sử dụng một lượng lớn dữ liệu để tính toán, sự kết hợp giữa phần cứng GPU và các thuật toán dựa trên CUDA có liên quan có thể làm giảm đáng kể thời gian hoàn thành các phép tính. GPU có thực sự kỳ diệu như vậy không? Chính xác thì những phần mềm và thuật toán này được GPU tăng tốc như thế nào?

QUÁ TRÌNH TÍNH TOÁN GPU
Làm thế nào để các tính toán của các ứng dụng này có thể được hoàn thành rất nhanh chóng phụ thuộc không chỉ vào GPU mà còn cả CUDA thúc đẩy các hoạt động này. Kể từ khi phát hành phiên bản 1.0 vào năm 2007, CUDA (Compute Unified Device Architecture) phiên bản 10.2 hiện đã có sẵn. Nói một cách dễ hiểu, nó là cầu nối giữa các nhà phát triển và GPU. Với công nghệ CUDA, các nhà phát triển quen thuộc với các ngôn ngữ lập trình khác nhau có thể viết chương trình để tăng tốc thuật toán thông qua GPU. Nguyên tắc cơ bản của việc sử dụng tăng tốc GPU thực sự rất đơn giản.
Máy tính chủ có bộ nhớ (RAM) chịu trách nhiệm truy cập dữ liệu và CPU chịu trách nhiệm cho các hoạt động, GPU cũng có bộ nhớ để truy cập dữ liệu và một chip cho các hoạt động (xem hình bên dưới). Trong một chương trình, tiến trình chính sẽ được điều khiển và cấp phát bởi CPU. Khi một chương trình nhất định được GPU tăng tốc, dữ liệu có thể được sao chép từ bộ nhớ chính sang bộ nhớ GPU thông qua cú pháp CUDA. Trong bước thứ hai, CPU gọi GPU để bắt đầu tính toán. Sau khi tính toán xong, CPU chỉ định cho GPU trả kết quả tính toán được lưu trong bộ nhớ GPU về bộ nhớ chính. Bằng cách này, quá trình tăng tốc GPU đã hoàn tất.
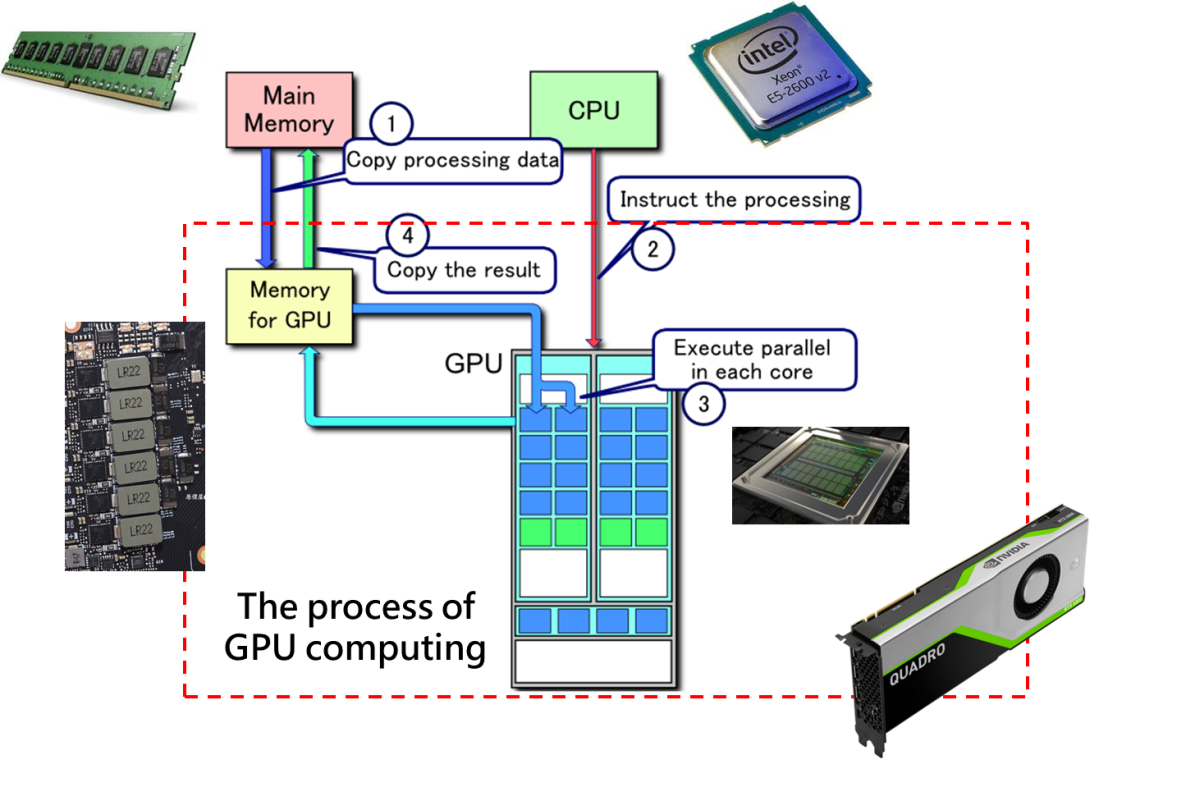
TẠI SAO GPU LẠI CÓ THỂ DÙNG ĐỂ TĂNG TỐC TÍNH TOÁN?
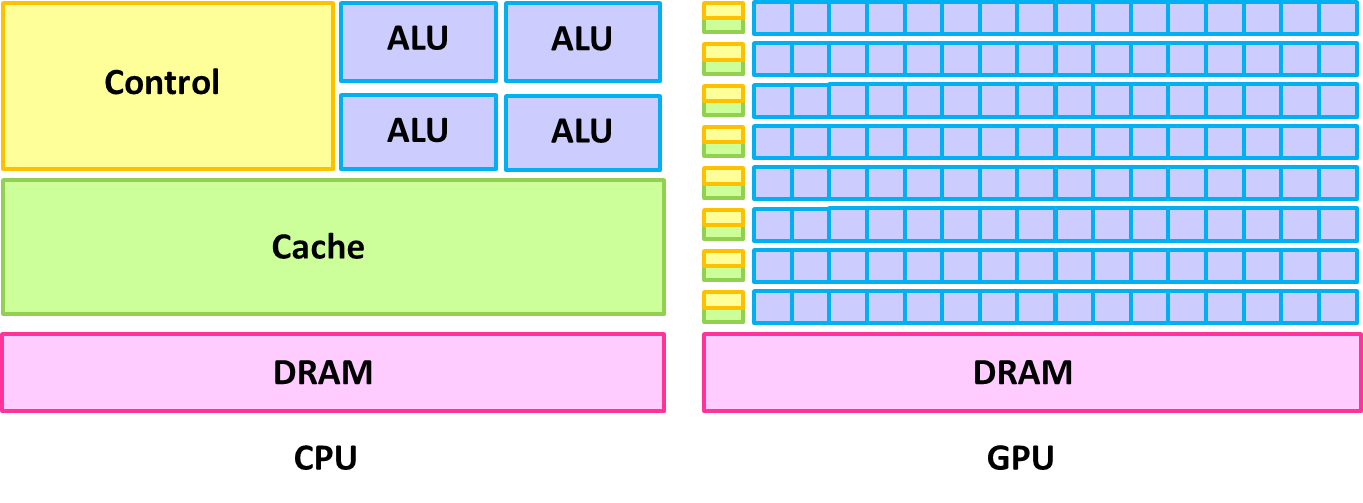
GPU và CPU rất khác nhau về bản chất. CPU có bộ nhớ đệm lớn hơn và nhân tính toán nhanh hơn, có thể xử lý các hoạt động phức tạp hơn. Nhưng GPU không có những đặc điểm như vậy; bộ nhớ đệm nhỏ hơn và hiệu suất đơn nhân kém hơn CPU. Tuy nhiên, GPU có một số lượng nhân điện toán khổng lồ (thường được gọi là CUDA Core), vì vậy lợi thế của nó là phù hợp để thực hiện một số lượng lớn hoạt động cùng một lúc. Một CPU cao cấp nhất có thể có tới 56 nhân (Intel Xeon Platinum 9282) và 112 luồng, nhưng một GPU cấp thấp (chẳng hạn như Quadro P620) có tới 512 nhân CUDA Core (bằng với số luồng ). Tất nhiên, điều này không có nghĩa là GPU mạnh hơn CPU mà là các loại máy tính phù hợp cho cả hai là khác nhau. Đặc điểm là GPU có số lượng nhân CUDA lớn phải được kết hợp với tính toán song song để tận dụng tối đa lợi thế của chúng. Do đó, như trong hình bên dưới, GPU có thể thực hiện các phép tính song song với tất cả các nhân trong khi CPU phải thực hiện điều đó theo thứ tự tuần tự. GPU được thiết kế cho máy tính chuyên sâu, tính toán song song cao cần thiết để xử lý hình ảnh. Tất cả các ứng dụng nói trên đều có đặc điểm là lượng dữ liệu tính toán lớn và tính song song cao nên chúng phù hợp nhất với tính toán GPU.
CÁCH SỬ DỤNG GPU ĐỂ TĂNG TỐC TÍNH TOÁN?
Có ba loại chính của hệ thống máy tính dùng tăng tốc GPU để xử lý:
- Sử dụng các gói phần mềm thương mại
- Sử dụng nguồn mở hoặc thư viện chính thức
- Lập trình CUDA
Sử dụng các gói phần mềm thương mại
Loại thứ nhất có rất nhiều loại, trong đó lĩnh vực phân tích phần tử hữu hạn là lớn nhất. Các tính toán liên quan trong lĩnh vực này bao gồm các ứng dụng như phân tích động lực học chất lỏng, phân tích độ dẫn nhiệt, phân tích trường điện từ hoặc phân tích ứng suất. Vì phạm vi bao gồm thiết kế vi mạch, thiết kế kiến trúc và thậm chí nhiều phương tiện hoặc nhà máy hóa chất cần thực hiện phân tích mô phỏng thông qua phần mềm như vậy, sự phát triển của phần mềm đó có giá trị thương mại lớn. Những ai muốn tìm hiểu thêm về các ứng dụng này có thể tham khảo các bài viết liên quan về ứng dụng GPU.
Sử dụng nguồn mở hoặc thư viện chính thức
Phần thứ hai này tùy chỉnh và linh hoạt hơn, vì người dùng phải viết chương trình của riêng mình và mô-đun tính toán GPU gọi các thư viện do người khác viết hoặc gọi thư viện chính thức do NVIDIA cung cấp. Các thư viện NVIDIA chính thức phổ biến nhất bao gồm thư viện tính toán ma trận cuBLAS, thư viện phân tích tần số cuFFT, thư viện học sâu cuDNN, v.v. và người dùng cũng có thể tìm kiếm chúng từ cộng đồng chẳng hạn như GitHub. Chẳng hạn chúng ta có thể tham khảo " ỨNG DỤNG TÍCH HỢP GPU " của NVIDIA cho hai mục trên. Nội dung bao gồm các phần mềm và bộ dụng cụ có thể sử dụng GPU trong nhiều lĩnh vực khác nhau và cung cấp phần giới thiệu, để các nhà phát triển có thể dễ dàng tìm thấy ứng dụng phù hợp.
Lập trình CUDA
Mục thứ ba phải được lập trình bằng CUDA, nhưng mức độ tự do thay đổi tùy theo ngôn ngữ lập trình. Trong số đó, ngôn ngữ lập trình cấp thấp hơn C / C ++ hoặc Fortran có mức độ tự do cao nhất và có thể điều khiển tính toán GPU với ngôn ngữ lập trình; chúng thậm chí có thể được tối ưu hóa để truyền dữ liệu bộ nhớ cục bộ và bộ nhớ GPU. Thứ hai là Python, cũng là ngôn ngữ lập trình chủ đạo nhất cho các ứng dụng trí tuệ nhân tạo. Các phương pháp triển khai bao gồm PyCuda hoặc sử dụng thư viện Numba. Người dùng PyCuda vẫn cần viết CUDA C trong nhân kernel. Tất nhiên, hiệu suất của nó gần như tương đương với việc viết CUDA C. Numba sử dụng trình trang trí để khai báo trong hàm và sử dụng chữ ký hàm để hoàn thành thiết lập gọi CUDA. Ngoài ra, Java, R, C #, v.v. cũng có thể hỗ trợ CUDA, nhưng chúng không trực tiếp như C / C ++ hoặc Fortran.
Nhận xét
Đăng nhận xét